


在处理和分析 pdf 文档时,有时候需要获取特定文本或图片的坐标信息。这些坐标信息可以帮助我们定位、提取和处理 pdf 中的特定元素。这篇文章将介绍如何使用 spire.pdf for python 和 python 获取 pdf 中文本或图片的坐标信息。
安装 spire.pdf for python
本教程需要用到 spire.pdf for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.pdf如果您不清楚如何安装,请参考此教程: 如何在 windows 中安装 spire.pdf for python
spire.pdf 的坐标体系
使用 spire.pdf 处理现有的 pdf 文档时,坐标的原点位于页面的左上角。x 轴从原点水平向右延伸,y 轴从原点垂直向下延伸(如下图所示)。
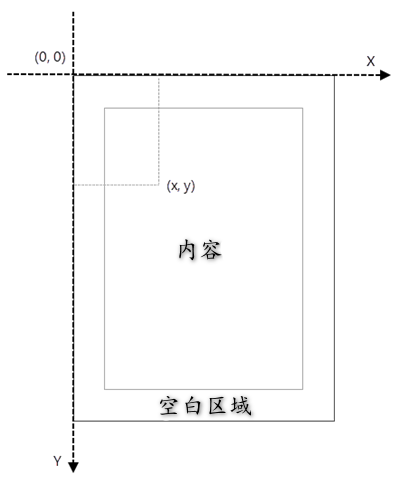
python 获取 pdf 中文本的坐标信息
要查找 pdf 文档中特定文本的坐标,需要先使用 pdftextfinder.find() 方法定位目标文本在特定页面上的所有实例。找到这些实例后,使用 pdftextfragment.positions 属性即可获取文本实例的精确(x,y)坐标。
获取 pdf 中指定文本的坐标的步骤如下:
- 创建 pdfdocument 对象。
- 加载 pdf 文档。
- 获取文档中的特定页面。
- 创建 pdftextfinder 对象。
- 通过 pdftextfinder.options 属性指定搜索条件。
- 使用 pdftextfinder.find() 方法在页面中搜索文本。
- 获取搜索结果的特定实例。
- 通过 pdftextfragment.positions[0].x 和 pdftextfragment.positions[0].y 属性获取该实例的 x 和 y 坐标。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建 pdfdocument 对象
doc = pdfdocument()
# 加载 pdf 文档
doc.loadfromfile("示例.pdf")
# 获取特定页面
page = doc.pages[0]
# 创建 pdftextfinder 对象
textfinder = pdftextfinder(page)
# 指定查找条件
findoptions = pdftextfindoptions()
findoptions.parameter = textfindparameter.ignorecase
findoptions.parameter = textfindparameter.wholeword
textfinder.options = findoptions
# 在页面中搜索字符串 "汽车"
findresults = textfinder.find("销售")
# 获取结果的第一个实例
result = findresults[0]
# 获取第一个实例的 x,y 坐标
x = int(result.positions[0].x)
y = int(result.positions[0].y)
with open("文本坐标.txt", "w", encoding="utf-8") as file:
file.write(f"找到的文本的第一个实例的坐标为: ({x}, {y})")
doc.dispose()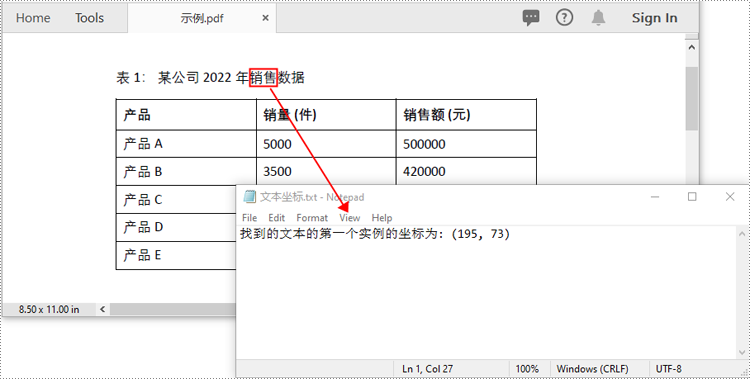
python 获取 pdf 中图片的坐标信息
spire.pdf for python 提供了 pdfimagehelper 类,允许用户从 pdf 文件的特定页面中提取图片的详细信息。提取后,可以利用 pdfimageinfo.bounds 属性来获取图片的(x,y)坐标。
获取 pdf 中指定图片的坐标的步骤如下:
- 创建 pdfdocument 对象。
- 加载 pdf 文档。
- 获取文档中的特定页面。
- 创建 pdfimagehelper 对象。
- 使用 pdfimagehelper.getimagesinfo() 方法从页面获取图片信息。
- 通过 pdfimageinfo.bounds 属性获取图片的 x 和 y 坐标。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建 pdfdocument 对象
doc = pdfdocument()
# 加载 pdf 文档
doc.loadfromfile("示例.pdf")
# 获取第一页
page = doc.pages[0]
# 创建 pdfimagehelper 对象
imagehelper = pdfimagehelper()
# 从页面获取图片信息
imageinformation = imagehelper.getimagesinfo(page)
# 获取第一个图片的 x,y 坐标
x = int(imageinformation[0].bounds.x)
y = int(imageinformation[0].bounds.y)
print("图片的坐标为:", (x, y))
doc.dispose()
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


